Service catalog
When I joined the on-call rotation at GitHub as we launched GitHub Actions, being on-call was something that was pretty new to me. I learnt a lot and had some amazing experienced colleagues who taught me a lot and there’s still so much to learn.
At one point GitHub had over 500 developers working 1 on the site and all the parts, spread out across the globe. It also interacted with teams at other companies, such as Microsoft and the Azure teams.
Navigating and understanding your services, teams and dashboards in an organization is hard, it was at GitHub. Repeatedly I’ve spoken to organizations building tooling to solve this internally.
Some of the problems you might have in your engineering organization 👇
Navigating your engineering services
As the size, speed and scale of your organization grows just navigating the teams grows harder. New people who join the company can struggle to find who does what and what’s important. Veterans struggle to keep up with changes.
What do those teams do? Who’s on the teams? Where do they hang out and communicate? What dashboards do they have?
If your answer is a document somewhere, a wiki, or so-on. The moment those documents are finished they are out of date.
Quality of your services
So you’ve got a series of services that make up your product. Those will be spread out across the organisation with different ideas and leaders. Spreading ideas and information out across those services and teams is hard.
Tools like Datadog, Splunk etc, are available to crunch all the run time information and provide you with good information about how users are using your service.
But there are other metrics and measurements within an organisation that you need to make sure are kept up to date. How many security issues are there on the service? Are they being dealt with quickly? Are legal requirements satisified? Is the team within compliance? Has the team got on-call rotation setup?
In a large organization you want to ensure that teams are meeting their goals before incidents happen.
How do we fix a problem?
Most of the time when an incident happened at GitHub we’d go through a progression that looked like this, in roughly this order:
- What just got deployed?
- What got migrated or transitioned?
- What just got turned on or off?
- What external services we depend on are having problems?
- What are users doing to the site?
In an incident you need concise and clear information as soon as you can to reduce your time to mitigation. Cognitive overload and lack of clarity in an incident slows everything down.
Even just knowing the key deployments and releases over the last hour and then the correct teams to contact - reduces the time to mitigate incidents the majority of the time.
Service catalog release
Over the last while I’ve been building a tool to do these things. The service catalog is tightly integrated into GitHub and GitHub Actions. Best of all, it’s free, open source and available for anyone to use straightaway.
Check it out here 👉 https://github.com/clearwind-ca/service-catalog
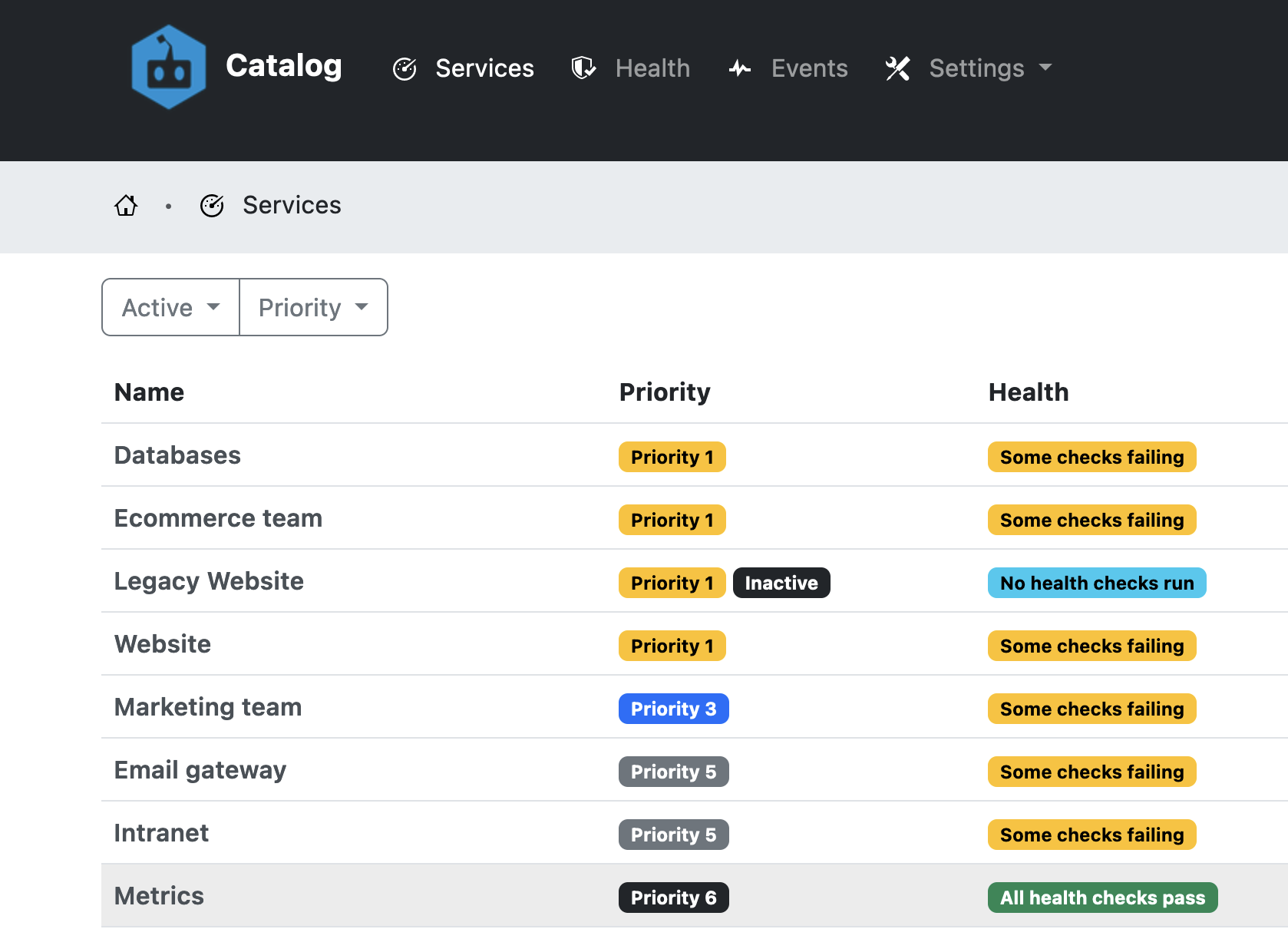
Watch this space for some more articles about it and if you are interested in using this, drop me a line.
–
-
This is an estimate, I don’t have the numbers and can’t remember the exact number 🤷♂ ↩